

“There are some genes we know a lot about, but there are many genes
we have no idea what they do. So, that’s the baffling part to me –
there is still so much work to be done just to figure out how it all works.”
– John McPherson, Ph.D., Baylor College of Medicine

Click here for Earthfiles Podcast.
January 18, 2007 Houston, Texas – The human body has about 100 trillion cells. Inside each of those cells is the nucleus that contains the genome—46 human chromosomes which have the blueprint for building a human body.
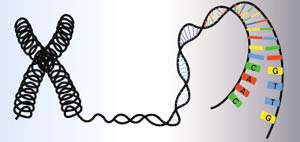
Each chromosome is one long string of DNA that is tightly coiled in a compact bundle. Chromosomes have the four “letters” of genetic code: A, C, G, T (adenine, thymine, cytosine and guanine) which pair off in nucleotides. Those nucleotides are laid out like zeroes and ones in computer software, but are bunched in groups of genes and long, puzzling non-coding sections. Those non-coding sequences are referred to as “junk DNA” and make up a surprisingly large 97% of the genome, which no one understands.
The Human Genome Project
“Human Genome Project.” We’ve been hearing those words since 1990 when the U. S. Dept. of Energy and U. S. National Institutes of Health formally created the project. The goal has been to identify all the genes in human DNA, the blueprint for a human body. Why the Dept. of Energy? Because since the creation of atomic bombs in the 1940s, scientists have tried to understand what radiation does to human bodies and what mutations it causes in human DNA.
After sixteen years and the hard work of 2,800 scientists around the world, there are some answers and surprises.
First, if you think of the human body as a book, then all of the pages and text together are the genome. The word was coined from genes and chromosomes. The DNA in every cell contains the whole book about how to make a human body.
The “words” in each genome “book” are the genes. The Human Genome Project expected to find at least 100,000 genes were necessary to create a human body. But one of the big surprises is the number of genes is only about 22,000, less than several other Earth creatures, especially plants – which have as many as 40,000 genes.
The main reason for the smaller number of genes than expected is that human genes are capable of multi-tasking the production of proteins. You might say the human genome book has a more advanced text, but it still takes 3 billion letters to write out those 22,000 words.
Now we come to the current main problem in the Human Genome Project: what is the punctuation in a string of 3 billion letters? Scientists have learned some sentence fragments, but do not know full sentences. That could take at least another decade to figure out how all those letters and words make our bodies work.
Another big puzzle is that inside some of the 22,000 genome “words” are strings of repeating “letters.” Imagine seeing a hundred letter g’s together and not having a clue why they are there. Scientists call long strings of repeating letters “non-coding sequences,” or “junk DNA.” Strangely, there is a lot of junk DNA in the human DNA molecule.
That’s why a January 11, 2007, Canadian blog by John Stokes and distributed on the web caught my attention. The headline was: “Scientists find extraterrestrial genes in human DNA.” Then the first paragraph stated: “A group of researchers working at the Human Genome Project indicate that they made an astonishing scientific discovery: They believe so-called 97% non-coding sequences in human DNA is no less than genetic code of extraterrestrial life forms.”
[ Editor’s Note: Scientists have long been puzzled by the fact that 97% of the DNA in human cells does not code for proteins and appears to consist of meaningless and repeating sequences. The possibility that this apparently useless DNA has some as yet unknown function continues to tantalize scientists.
See: F. Flam, “Hints of a language in junk DNA,” Science 266:1320, 1994.]

The Canadian blog says the name of the Human Genome Project “group leader” responsible for the discovery that junk DNA is genetic code of E.T.s is Prof. Sam Chang. I could not find any Google listing for Prof. Sam Chang, so I decided to get a reality check on the truth from John McPherson, Ph.D. Dr. McPherson is currently Associate Professor in the Dept. of Human and Molecular Genetics at Baylor College of Medicine in Houston, Texas. Over the past ten years, Dr. McPherson was also Co-Director of the Genome Center at Washington University in St. Louis. There, he was the lead scientist in that university’s efforts to map the human genome, as well as mouse and chicken genomes. I began by asking him: What is junk DNA?
Interview:
John McPherson, Assoc. Professor, Dept. of Human and Molecular Genetics, Baylor College of Medicine, Houston, Texas, and former Co-Director of the Genome Center, Washington University, St. Louis, Missouri: “That still remains to be seen. But it could be many different things. There are some of the DNA that we have termed ‘junk’ in the past, which might have been essentially a virus that infected us and jumped around and made copies of itself within our DNA. Then over time – because eventually over time that would destroy us – it was quieted down, but its remnants are still there. There are definitely pieces of DNA that are still mobile within our genome, but they are just very quiet. You can activate these things artificially in cell culture, for example. You can get them to jump all over the place. There are cases where diseases have been shown to be caused by one of these elements moving into a gene in an individual. It then gets propagated in their family and that causes the disease. So there are what we call mobile elements in the genome. Where they come from originally is a good question. But there is the theory they are just basically viruses that came along and tagged along with us.
Genomes are growing and expanding and some are decreasing. So, the junk DNA – right now it might have a role in that the spacing it puts in our genes might be required. We don’t really know.
HOW LONG DO YOU THINK IT WILL BE BEFORE YOU REALLY DO KNOW?
I don’t know. I mean, we certainly have some ideas of what things are doing, but I think in the next ten years, we’ll have a better idea.
IT WILL TAKE AN ENTIRE OTHER DECADE?
I believe it will another decade to figure out much of the genome. Even then, there will still be a lot of questions. But just even to come up with what we think are all the genes and how they interact with each other is at least another decade.
WOW, THAT’S 2017!
Yep. Getting the sequence was just the start. It really was. It took a long time to get it. That was a 15-year-long project from the beginning. Not all sequencing was done in the last few years, but it was all the preparation before that in learning how to do it. Now that we have the (human genome) sequence, we have to figure out what it does. And that’s one of the reasons we’re sequencing lots of other genomes so we can compare them and by comparing them, figure out what things do. So, there’s lots more to be done.
IS THERE ANYTHING YOU’VE FOUND THAT WOULD FALL INTO THE CATEGORY OF BAFFLING, UNEXPLAINED, IN THE SEQUENCING OF THE HUMAN GENES?
I think the biggest thing that is baffling to me is how it all works. We have – it’s often referred to as the ‘Parts List.’ We know the genes, we can look at them, but we still have to figure out what they do. Just by looking at the sequence, we can’t – there are some we can predict what it does, but there are many that we can’t. It’s still a big puzzle. It’s just like an analogy might be a jigsaw puzzle where you’ve got all the pieces, but you don’t have the box that shows you what the picture is. And you have to put it together. And figure out what it all is. We’re sort of in that stage in many ways. There are some genes we know a lot about, but there are many genes we have no idea what they do. So, that’s the baffling part to me – there is still so much work to be done just to figure out how it all works.
Canadian Blog – Who Is Prof. Sam Chang?
HAVE YOU EVER HEARD OF A SCIENTIST NAMED PROF. SAM CHANG?
Sam Chang. Not, it does not ring a bell.
SO YOU PERSONALLY HAVE NOT WORKED WITH HIM ON THE GENOME PROJECT? SAM CHANG?
No, not that I’m aware of. There are a lot of people involved we never got to meet, but we only met through emails. But that name does not ring a bell.
IN THE CAPACITY YOU HAD IN ST. LOUIS AND TODAY, SHOULD YOU KNOW MOST OF THE MAIN PEOPLE?
Most of the main characters, yes. Although it was very international and there were some labs that we never got to go to or meet the people from. So, some of the names don’t stick in my head from back then.
THE REASON I’M ASKING IS THAT I HAVE A JANUARY 11, 2007, CANADIAN BLOG ABOUT A PROF. SAM CHANG SAYING THAT HUMAN JUNK DNA HAS NOW BEEN PROVED BY THE HUMAN GENOME PROJECT TO BE FROM SOME KIND OF EXTRATERRESTRIAL CODING.
(laughs) Well, I’ve never heard of that! (laughs) I’ve never heard of that before and it certainly does not sound very credible to me. But I haven’t seen the article. [ I give him the URL.]
I WONDER HOW THIS LONG ARTICLE WAS MADE UP?
Actually I’m just looking on the web while I’m talking to you. If you do a search, there are all sorts of things pointing towards that.
WHERE WOULD THIS INFORMATION AND NAME, PROF. SAM CHANG, COME FROM?
I don’t know. (laughs) I find it actually kind of funny.
Panspermia
SINCE YOU ARE AN EXPERT IN GENETIC RESEARCH, CAN YOU AT LEAST COMMENT ON THE POSSIBILITY THAT HOMO SAPIENS SAPIENS MIGHT HAVE BEEN SEEDED BY LIFE FROM SOME PLACE ELSE AND IT MIGHT SHOW UP IN SOME WAY IN OUR HUMAN GENOME SEQUENCING PROJECT?
Well, as far as I know, there is no evidence to support that. So, this is all news to me.
CRICK AND WATSON WON THE NOBEL PRIZE FOR DESCRIBING THE DOUBLE HELIX DNA MOLECULE – AT LEAST 50 YEARS AGO?
1953, I think.

I KNOW THERE WAS A PAPER CRICK PUBLISHED IN ICARUS WITH BIOCHEMIST, LESLIE ORGEL. THEIR HYPOTHESIS WAS THAT BECAUSE THERE IS THE SAME SPIRAL DNA MOLECULE IN ALL LIFE ON EARTH – WHICH THE SCIENTISTS DID NOT THINK COULD HAPPEN ACCIDENTALLY – THEN IT MEANT PANSPERMIA, THE ACT OF SEEDING DNA ON THIS PLANET FROM OUTSIDE HAD TO HAVE BEEN OUR ORIGIN.
[ Editor’s Note: “Directed Panspermia,” Icarus, International Journal of Solar System Studies, Vol. 19, No. 3, July 1973 by F. H.C. Crick and L. E. Orgel, © 1973 Academic Press, Inc.]
Right, I’ve seen theories like that where people believe that DNA or bacteria or something came to Earth on an asteroid or what have you and that DNA and RNA weren’t formed in the bubbling oceans of the world. Anything is possible because they are all theories at this point. We don’t know for sure where things came from, so it is possible that the first DNA came to the world from outside and then evolved. Whether you want to bring up religious arguments, I think that’s fine, too. They can all in a way fit into the same arguments. You could say the first DNA was seeded by God. Or you can say it came from an extraterrestrial source? Who knows?
WOULD YOU AGREE WITH ORGELL, CRICK AND THAT GROUP THAT IT IS IMPOSSIBLE ALL EARTH LIFE WOULD HAVE EXACTLY THE SAME DNA?
It’s an interesting observation. You might think if it was all coming from the primordial soup, so to speak, that there might be different sources that came up with different ways of doing (life). There are, for example, RNA viruses which have only RNA and don’t have any DNA. So, some of the theories re that the RNA came first and the DNA evolved later.
I don’t know. It might be that it’s such a rare event for it to happen at all that it (panspermia event) did seed everything. I think any theory is just as likely as the next at this point in time.
WOULD YOU AND YOUR COLLEAGUES HAVE ANY WAY OF IDENTIFYING SOMETHING THAT WAS INTRODUCED IN THE GENE SEQUENCE THAT WOULD SEEM HIGHLY ARTIFICIAL TO YOU, SUCH AS EXTRATERRESTRIAL PROGRAMMING, COMPARED TO THE REST OF HUMAN GENOME SEQUENCING?
Probably not. If you look hard enough, you’ll find patterns in anything and depending on how you want to interpret them. For example, there’s lots of articles by people who say if you take every 5th letter of every 3rd word of the Bible, you spell out this or that. Genes are the same sort of thing. If you look at patterns long enough and find different ways of looking at them, you will eventually find something by chance.
So, whether we would recognize something, I don’t think we would be able to recognize it (E. T. genetic manipulation) as being anything out of the ordinary. We can certainly recognize patterns within the DNA. But what maybe we don’t understand yet what they do and they might be involved in the structure of the DNA and how it is all compacted into each cell. We just don’t know that yet.
THE BOTTOM LINE IS THAT EVEN IF HOMO SAPIENS SAPIENS WAS THE PRODUCT OF SOME KIND OF SEEDING AND THEN GENETIC MANIPULATION BY OTHER THAN HUMAN INTELLIGENCES, THAT HUMANS WOULD NEVER BE ABLE TO DIFFERENTIATE BETWEEN THE CURRENT DNA THAT THEY ARE AND IT HAVING BEEN MANIPULATED BY ANOTHER INTELLIGENCE?
It would be unlikely to have, to be certain, that’s for sure. I think you could look at a lot of patterns and come up with a lot of things, but I think someone else can look at it just a little different way and see something different. I think people will see what they want to see in the patterns.
No Sexual Link Between Neanderthalis and Homo Sapiens
THIS COMES TO THE WORK OF PABLO SVANTE, WHO HAS BEEN ANALYZING AN ELBOW THAT WAS FOUND IN A GERMAN CAVE. THEY THINK THE CAVE WENT BACK TO THE END OF NEANDERTHALIS ABOUT 40,000 YEARS OLD?
Right.
IF THERE ARE AT LEAST 19 MAJOR DIFFERENCES BETWEEN THE GENOME SEQUENCING ON THE NEANDERTHALIS BONE COMPARED TO MODERN HOMO SAPIENS SAPIENS. THE CONCLUSION WAS THAT THERE COULD NOT HAVE BEEN SEXUAL INTERCOURSE BETWEEN NEANDERTHALIS AND CRO MAGNON HOMO SAPIENS SAPIENS.
I don’t know – there are certainly more differences than nineteen. It’s very difficult sequencing because most of the samples are contaminated with modern DNA. So, it’s difficult to sort out the Neanderthal sequences from the modern human. But there are a few samples that are supposedly uncontaminated. But DNA is not stable, either. Over time it changes. So, the other problem you have is determining which changes are real and which are things that have happened to the DNA over time. So, the DNA degrades in such a way that bases change. So, when we sequence them, we see a different base there than was actually there at the time. And there are ways to estimate that error rate based on other things in the bone.
But you still have to apply the rate of change to what you are seeing and come up with some conjecture of the number of errors, or differences, that are there. So, I think it is still very early on to be analyzing that data to make any statements whatsoever about it.
IF THERE WERE NO SEXUAL CONNECTION BETWEEN THE NEANDERTHALIS LINE AND HOMO SAPIENS SAPIENS THAT CAME LATER, WHERE DID CRO MAGNON HOMO SAPIENS SAPIENS COME FROM?
Well, they didn’t have to breed together to diverge, right? I mean they could be geographically isolated offshoot in evolution, which evolved independently. I mean, if we all evolved throughout time out of Africa, there could definitely be groups that were geographically isolated and have evolved independently.
BACK TO THE ORGELL/CRICK PANSPERMIA HYPOTHESIS, IF THERE WAS MANIPULATION OF DNA IN ALREADY-EVOLVING PRIMATES ON THE PLANET, THEN IT’S POSSIBLE THAT HOMO SAPIENS OR NEANDERTHALIS OR EVEN HOMO ERECTUS COULD HAVE BEEN THE PRODUCT OF SOME KIND OF GENETIC TAMPERING?
I don’t believe that. If you look at all over the planet, there are species of birds, for example, that are clearly related, but cannot inter-breed. How did they all become different? Well, they became different because they were isolated in different areas and they started to evolve and adapt to the local environment, so the beak changed so some could eat certain things. And then, as they changed and evolved, the chromosomes changed enough that they could no longer interbreed. But they are all very, very related and can be connected back to some progenitor bird. So, the fact that they are different doesn’t mean that anyone manipulated them, they just changed over time.
No Way to Prove Genetic Manipulation of Already-Evolving Primates by E. T.s?
SO THE BOTTOM LINE TO ALL OF THIS IS: EVEN IF THERE WERE AN EXTRATERRESTRIAL MANIPULATION OR SEEDING OF DNA ON THIS PLANET OR OTHER PLANETS, OUR CURRENT LIFE FORM RIGHT NOW – HUMANS – WOULD NEVER BE ABLE TO PROVE IT?
I would think probably that we could not prove it. It would be very difficult for us to prove that. It’s very difficult to prove anything in the past, right? All you can do is look at the evidence and come up with a theory. But proof is something that you can just come up with the facts based on the current data and you can formulate a theory. And a theory is something that’s not just a wild story. It’s something that is sort of accepted to be what happened in the past, or what will happen in the future, based on what scientists believe. So, it’s sort of the accepted, current knowledge. But to actually prove something is extremely difficult.
Surprisingly Few Genes Needed to Make Humans
AN M.I.T. HEADLINE IN 2004 WAS ‘THE NUMBER OF GENES IN THE HUMAN GENOME IS LOWER THAN PREVIOUSLY ESTIMATED’ – CONSIDERABLY LOWER. COULD YOU ELABORATE AND EXPLAIN THIS?
When we started sequencing the genome, the prediction was that there would be 100,000 human genes. That prediction was based largely on the few genes that had been sequenced. Their size was around 30,000 base pairs. Since the human genome was 3 billion base pairs, just doing the math, it seemed that if the average gene was 30,000 base pairs, then there would be 100,000 genes (in a human). I think that is sort of a simplistic view of where that 100,000 number came from.
Of the things that had been sequenced at the time, a worm was being sequenced and it looked like 20,000 genes in it. So, it seemed reasonable – maybe it was part of our arrogance – that we thought there should be 100,000 human genes.
But in the end, when we sequenced the human genome, it turned out to be – and it’s still a debatable point actually how many genes there are (in humans) – but there are maybe something like 22,000 human genes. The difference is not the number of genes, but the complexity of the genes that has more to do with the complexity of the organism.
IF I UNDERSTAND WHAT YOU JUST SAID, YOU MEAN IF HUMANS HAVE 22,000 GENES AND OTHER CREATURES MIGHT HAVE 30,000 GENES OR MORE, THEN OUR GENE SEQUENCING IS MORE COMPLEX?
In human genes, one gene tends to make multiple proteins, whereas a lot of things like the worm it’s one gene makes one protein. Our human genes make at least two proteins on average. Some genes make many, many proteins. It’s called ‘differential splicing’ and it’s a way of mixing and matching parts within that gene to make a different protein for a different function. So human genes get more complexity out of the genes that we have than something like a worm.
IS THERE OTHER EARTH LIFE THAT IS SIMILAR TO OUR GENE SEQUENCING IN COMPLEXITY?
In complexity – yes. We have sequenced some of the primates such as chimpanzee and macaque and they have very similar genomes to our own – and almost any mammalian genome, including cows, which have been sequenced. All of those genomes have roughly about the same number of genes as humans.
I think the largest numbers of genes have been in plants actually. Some plants have 40,000 genes and some of that is that plants tend to be chemical factories. They produce a lot of compounds to protect themselves from insects since they can’t run away like we can. They are stuck in one spot and so they have lot of chemical synthesis machinery. That might account for a lot of the genes that they have.
WHICH IS CLOSEST OTHER EARTH LIFE TO HOMO SAPIENS?
Chimpanzee, but we haven’t finished sequencing all the other primates yet, though.
Looking for Disease Causes in Genes
WHAT IS CURRENT FOCUS OF YOUR WORK RIGHT NOW?
Right now we are using the information we have to go in and sequence genes within individuals looking for the cause of disease – we’re looking for differences in the genes (compared), which might then be related to the diseases that we’re studying.
COULD YOU GIVE AN EXAMPLE OF SOMETHING WE WOULD ALL KNOW AND HOW THIS WORK HAS APPLIED?
We have a number of projects going on: epilepsy, obesity, many others. We’re looking at cancer as well. The idea is that we pretty well know what a normal gene looks like by doing the human sequencing, so we’re looking now for variations on those genes which might be associated with disease.
IS THERE A PARTICULAR DISEASE LINK THAT YOU THINK IS ABSOLUTELY FIRM THAT MIGHT BE A DISEASE WE WOULD BE SURPRISED ABOUT?
I’m always surprised. I’m surprised every day by things that we see. I don’t know about surprises – what we’re finding, I think, and it’s early days – but many of the diseases we’ve known about in the past like cystic fibrosis – there was a very definite change in the gene that we could associate with the disease. Now, what we’re looking at are what we call complex disorders where it may be subtle variations in a number of genes, which all add up to give you the disease. In the subtle variations, you may find that someone without the disease have some of those. But having all of them together is what gives the disease. So it can be very difficult to tease it out.
That’s why we are sequencing lots of diseases in a lot of people looking for these associations where a change in this gene is not enough to give you the disease, but a change in Gene 1 plus the change in Gene 2 plus the change in Gene 3 all add up to give you the disease.
I think the surprising thing is that what we are seeing is how much variations there are in all the genes in all of us. But it depends on how they mix and match whether you get heart disease or other.”
More Information:
For further information about human genetic history, please see the Earthfiles Archives below:
- 12/14/2006 — Abductee Jim Sparks’s Encounter with Reptillian Beings, Their Warning and Possible Agenda
- 10/11/2006 — Part 2: Time Travel, Insights from USAF Sergeant and UFO Abductee
- 10/08/2006 — Part 1: Time Travel, Insights from USAF Sergeant and UFO Abductee
- 09/29/2006 — Manipulation of Time and Matter by Non-Humans: The Experiences of Jim Sparks
- 05/12/2006 — An Extraterrestrial School for Humans
- 10/10/2004 — Part 1: Texas Case of Shape-Shifting Human-to-Reptilian
- 02/25/2003 — Part 2 – Corguinho, Brazil: Inside the Non-Human Craft from September 15 – 18, 2002
- • 01/11/2003 — Part 4: Tall, Red-Haired Extraterrestrials – The Abduction and “Transformation” of Brian Scott
Websites:
National Human Genome Research Institute: http://www.genome.gov/
Dept. of Energy: http://www.ornl.gov/sci/techresources/Human_Genome/home.shtml
Nat’l. Institutes of Health: http://www.genome.gov/10001772
© 1998 - 2026 by Linda Moulton Howe.
All Rights Reserved.